Elixir 学习笔记(2):基本类型
接下来让我们看看 Elixir 语言中有哪些基本类型。
基本算术
打开 iex 并输入以下表达式:
iex> 1 + 2
3
iex> 5 * 5
25
iex> 10 / 2
5.0
iex> 3 / 2
1.5有没有发现,后两个输出竟然是浮点数,这大概因为 Elixir 是动态类型语言。那么,如何在 Elixir 中进行整除运算呢?
iex> div(10, 2)
5
iex> div 10, 2
5
iex> rem 10, 3
1使用 div 和 rem 函数即可进行整除和取余运算。注意,他们是函数而不是运算符,只不过,Elixir 允许你在调用至少有一个参数的命名函数时去掉括号。这个特性让编写声明和控制流结构的语法更简洁,然而,Elixir 开发者通常更喜欢加上括号。
Elixir 支持表示二进制、八进制、十六进制数的字面量。
iex> 0b1010
10
iex> 0o777
511
iex> 0x1F
31还支持科学计数法,注意,e 之前必须为浮点数而不能是整数(1.0 而不能是 1)。
iex> 1.0e10
10000000000.0Elixir 中,浮点数类型是 64 位双精度的。
round 函数可进行舍入计算,trunc 函数可进行向下取整(trunc 是单词 truncate 截断的缩写)。
iex> round(3.58)
4
iex> trunc(3.58)
3标识函数和使用文档
Elixir 中通过函数名和参数数量确认一个函数,如 trunc/1 表示某个函数名为 trunc 并接受一个参数,trunc/2 表示某个函数名为 trunc 并接受两个参数(当然,这个函数并不存在)。通过这种语法就可以查询函数文档。
iex> h trunc/1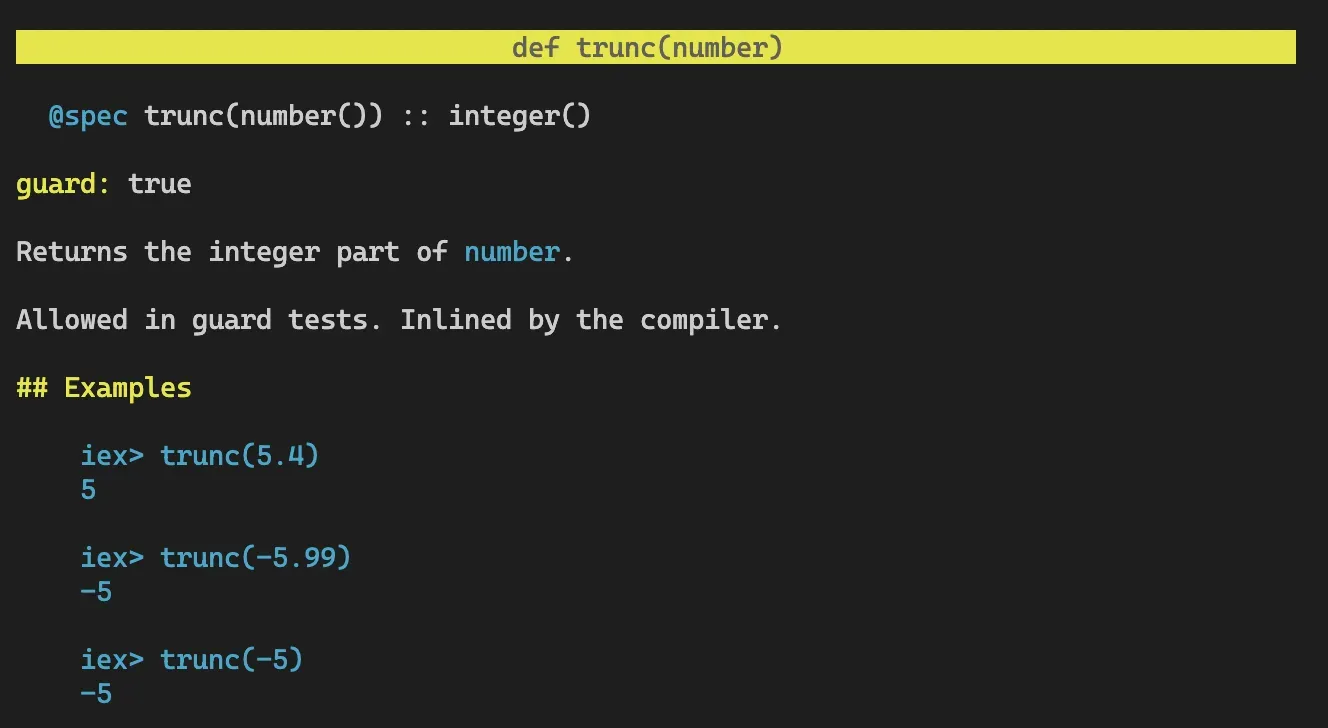
为什么我们能够直接使用 trunc/1 函数?因为它被定义在 Kernel 模块中,所有在该模块中的函数都会被自动引入命名空间中。所以输入 h Kernel.trunc/1 会得到和上面相同的结果(实际上大多数情况下,查询函数时都需要加上模块名。)。
除了普通函数,运算符也适用于这种语法,如 1 + 1 中的 +。
iex> h Kernel.+/2当只输入 h 而不加任何参数时将显示 IEx.Helpers 的文档。(这似乎违背了括号省略规则?)
布尔
iex> true != true
falseElixir 提供了很多断言函数用以检测某值的类型。
iex> is_number(1.0e10)
true原子
原子类型的变量是一种常量,其值就是其名,这种变量常被用于枚举不同值。某些语言(如 JavaScript)称 atom 为 symbol。
某个操作的状态常用 :ok 或 :error 来表示,他们都是原子。
iex> true == :true
true
iex> is_atom(false)
true
iex> is_boolean(:false)
true布尔值 true 和 false 也是原子,只不过在 Elixir 中,使用 true、false 和 nil 这三个特殊原子值时可以省略 :。
最后,Elixir 中有一种叫做「别名」的结构。别名以大写字母开头,也是原子。
iex> is_atom(Hello)
true字符串
Elixir 中的字符串由双引号括起,使用 UTF-8 编码。
iex> "你好"
"你好"即使到了 2202 年,Windows 终端仍不默认使用 UTF-8,所以在进入 Iex 之前,可以在命令提示符(PowerShell 无效)中输入
chcp 65001以改变编码。
Elixir 支持字符串插值。(这也是 atom?)
iex> string = :世界
:世界
iex> "你好,#{string}"
"你好,世界"Elixir 支持多行字符串。
iex> "hello
...> world"
"hello\nworld"
iex> "hello\nworld"
"hello\nworld"使用函数 IO.puts/1 可以打印字符串。
iex> IO.puts("hello\nworld")
hello
world
:ok注意,这个函数在打印结束后返回了原子值 :ok。
Elixir 中的字符串在内部以相邻的字节序列存储,也就是二进制。
iex> is_binary("你好")
true我们可以获取字符串的字节数。
iex> byte_size("你好")
6这个数之所以远远大于字符串的字符数是因为每个汉字在 UTF-8 中需要 3 B 来存储,想要计算实际字符数,需要函数 String.length/1。
iex> String.length("你好")
2String 模块中有很多函数,这些函数能够操作 Unicode 标准中定义的字符串。
iex> String.upcase("βίος")
"ΒΊΟΣ"匿名函数
iex> add = fn a, b -> a + b end
#Function<12.71889879/2 in :erl_eval.expr/5>
iex> add.(1, 2)
3
iex> is_function(add)
true注意,调用匿名函数时需要在变量名与括号之间加上 .,这是为了区分匿名函数和具名函数。
此外,如果想要在判断类型时加上函数参数数量这个条件,可以使用函数 is_function/2。
iex> is_function(add, 2)
true
iex> is_function(add, 1)
false最后,匿名函数能够访问定义时所在作用域的其他变量,也就是闭包(捕获)。让我们定义另外一个匿名函数,并在其中使用到刚才定义的 add。
iex> double = fn a -> add.(a, a) end
#Function<6.71889879/1 in :erl_eval.expr/5>
iex> double.(2)
4在函数内部进行赋值不会影响外部变量。
iex> x = 42
42
iex> (fn -> x = 0 end).()
0
iex> x
42列表(链表)
Elixir 使用方括号定义列表,元素类型任意。
iex> [1, 2, true, 3]
[1, 2, true, 3]
iex> length [1, 2, 3]
3运算符 ++/2 和 --/2 用来连接两个列表或让两个列表相减。
iex> [1, 2, 3] ++ [4, 5, 6]
[1, 2, 3, 4, 5, 6]
iex> [1, true, 2, false, 3, true] -- [true, false]
[1, 2, 3, true]作为一门函数式语言,Elixir 中的数据结构不可变,也就是说,对列表的操作只会创建新列表而不会修改原列表。另一方面,所有函数都是纯函数,如果不通过返回值接收运算结果,什么都不会被更改。
列表的头是其第一个元素,可通过 hd/1 获取;列表的尾是其他元素,可通过 tl/1 获取。
iex> list = [1, 2, 3]
iex> hd(list)
1
iex> tl(list)
[2, 3]获取空列表的头或尾会报错。
iex> hd([])
** (ArgumentError) errors were found at the given arguments:
* 1st argument: not a nonempty list有时创建列表时会返回一个用单引号括起的值。
iex> [11, 12, 13]
'\v\f\r'
iex> [104, 101, 108, 108, 111]
'hello'当某个列表中的值都是可打印的 ASCII 字符,Elixir 会将其看作字符列表,这个类型在与 Erlang 交互时很常见。
在 IEx 中可以使用 i/1 来查看某个值的详细信息。
iex> i 'hello'
Term
'hello'
Data type
List
Description
This is a list of integers that is printed as a sequence of characters
delimited by single quotes because all the integers in it represent printable
ASCII characters. Conventionally, a list of Unicode code points is known as a
charlist and a list of ASCII characters is a subset of it.
Raw representation
[104, 101, 108, 108, 111]
Reference modules
List
Implemented protocols
Collectable, Enumerable, IEx.Info, Inspect, List.Chars, String.Chars注意,Elixir 中单引号用以表示字符列表,双引号用以表示字符串,两者类型不同,并不等价。
iex> 'hello' == "hello"
false元组
Elixir 使用大括号定义元组,元素类型任意。元组的元素在内存中连续存储。
iex> tuple = {:ok, "hello"}
{:ok, "hello"}
iex> elem(tuple, 1)
"hello"
iex> tuple_size(tuple)
2
iex> put_elem(tuple, 1, "world")
{:ok, "world"}
iex> tuple
{:ok, "hello"}和列表情况类似,put_elem/3 不会更改原元组。
元组常用于函数返回值。(Go 的 T, error,Rust 的 Result<T, E>)
iex> File.read("path/to/existing/file")
{:ok, "... contents ..."}
iex> File.read("path/to/unknown/file")
{:error, :enoent}例如,对于函数 File.read/1,如果成功读取文件,则返回一个包含原子值 :ok 和文件内容的元组,否则返回包含原子值 :error 和错误信息的元组。
列表和元组有什么区别?
Elixir 的列表其实是链表,也就是说,获取其长度的时间复杂度为
同样地,列表连接的性能取决于左侧列表的长度:
iex> list = [1, 2, 3]
[1, 2, 3]
# 这比较快,因为遍历时只经过一个元素
iex> [0] ++ list
[0, 1, 2, 3]
# 这比较慢,因为遍历时经过三个元素
iex> list ++ [4]
[1, 2, 3, 4]而元组在内存中连续存储,也就是说,通过索引访问元素和获取大小的时间复杂度都是 length、size 之类的字段,可直接获取。另外,虽然 C 中的数组没有这种特性,但 sizeof 运算符能够在编译期确定数组所占内存空间大小(前提是没有降级为原始指针),所以在运行期也可直接获取。)。然而,更新或添加元素到元组时需要在内存中创建一个新元组,代价昂贵:
iex> tuple = {:a, :b, :c, :d}
{:a, :b, :c, :d}
iex> put_elem(tuple, 2, :e)
{:a, :b, :e, :d}这就是顺序存储和链式存储的不同,一个能够随机访问,便于细节操作(如查找、修改);一个能够循序访问,便于整体操作(如添加、删除、连接、分割、交换)。
数据结构特性不同导致 Elixir 中两种类型的 API 设计不同,如列表能通过 ++/2 进行连接,元组不能;元组能通过 elem/2 访问其中的某个元素,列表不能。
iex> tuple = {'Hello', "Daniel"}
{'Hello', "Daniel"}
iex> list = elem(tuple, 0)
'Hello'
iex> IO.puts(list ++ ['W', 'o', 'r', 'l', 'd'])
HelloWorld
:ok可变与不可变
结构化编程限制了
goto,面向对象编程限制了函数指针,函数式编程限制了可变变量。⸺《架构整洁之道》
实际上 Elixir 并不是那种彻头彻尾的函数式风格,在 Haskell 这种学术性极强的纯函数式语言中,「定义」取代了「赋值」,一切变量都是不可变的,不存在状态保存,一切都是纯函数间无副作用的运算。这听起来很不可思议,但实际上,数学运算就是如此。1
这样做的好处是,代码抽象程度极高,有完备理论支撑,不存在数据竞争。但反过来,过于抽象的代码不易编写和理解(讲个笑话,自函子范畴上的幺半群),可维护性低,往往不适合解决实际问题。此外,「可变性」这一特性的缺失会影响程序性能。23
用 Elixir 的元组举个例子:假设数据结构是可变的,更新元素时直接更改即可;但在不可变的情况下就要额外在内存中分配空间用以存储修改后的新元组。不过 Elixir 对此也有优化,因为不可变性,我们可以存储数据的引用而无需担心数据被修改,这在一定程度上减少了程序的内存分配量。(官网教程上说当更新元组时,除了被替换的元素外,新、旧元组之间共享所有元素。私以为这种「共享」通过引用实现,但所有类型都用引用存储反而增加了时间和空间上的损耗,并不合理,虽然是动态类型,也应该对不同类型进行不同处理。45)
总结一下,编程范式进化的实质是通过更多概念限制操作,远离底层,提高抽象能力,但这并不代表其中的某个一定更好用、更高级。任何编程范式都不是银弹,根据实际场景合理使用多种范式才是正确的。
大小 size 与长度 length
Elixir 中用以获取某种类型大小或长度的函数遵守以下规则:如果时间复杂度为 size;如果时间复杂度为 length。(记忆技巧:「length」(长度)和「linear」(线性的)都以「l」开头。)
例如:
byte_size/1:字符串的字节数tuple_size/1:元组大小length/1:列表长度String.length/1:字符串的字符数
显然,获取大小始终是廉价的,而计算长度会随着数据的增长变得昂贵。
Array x List x Tuple
所以说他们究竟是什么已经不重要啦,不同语言有不同的设计,size 和 length 的区别也是如此,上文内容仅针对于 Elixir。
如果非要总结的话:
- Array:顺序存储,类型一致,长度固定
- List:可扩充
- Tuple:可同时存储多种类型
除了上述基本类型,Elixir 还提供了数据类型 Port、Reference 和 PID(常用于进程通信),探讨进程时会介绍他们。